DeepSeek 的出现使得本机部署 LLM 模型的硬件需求降到一个很低的标准,该教程利用 Docker 搭建 ollama 服务,并通过 open-webui 提高交互体验。
搭建 Ollama 服务
这里假设 Docker 环境与 nvidia-runtime 均已配置完成。
创建 docker-compose.yaml 文件
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
|
services:
ollama:
image: ollama/ollama:latest
container_name: ollama
network_bridge: bridge
restart: unless-stopped
deploy:
resources:
reservations:
devices:
- driver: nvidia
count: 1
capabilities:
- gpu
- compute
- video
ports:
- 11434:11434
volumes:
- data:/root/.ollama
volumes:
data:
|
执行以下命令启动服务:docker-compose up -d
通过 docker logs ollama 可以查看运行日志,看到 Listening on [::]:11434 的字样则表示启动成功。
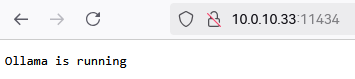
浏览器打开 ip:11434,可以看到显示 Ollama is running
安装 Open WebUI
这里我们依然选择使用 docker 的方式安装 open-webui。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
|
services:
openwebui:
image: ghcr.io/open-webui/open-webui:main # 或者包含 Nvidia GPU 支持的 cuda 标签
container_name: open-webui
network_mode: bridge
restart: unless-stopped
# deploy:
# resources:
# reservations:
# devices:
# - driver: nvidia
# count: 1
# capabilities:
# - gpu
# - compute
# - video
# 如果想不用登录就使用则去掉下面两行的注释
# environment:
# - WEBUI_AUTH=False
ports:
- "127.0.0.1:8000:8080"
volumes:
- data:/app/backend/data
volumes:
data:
|
启动后观察日志,出现 Uvicorn running on http://0.0.0.0:8080 则表示启动完成。
配置 Open WebUI
打开浏览器,访问 127.0.0.1:8000 (后续可以通过 nginx 反代 https),按照提示输入密码后登录网站。
点击右上角的头像图标,选择 管理员面板,切换到 设置 选项卡,选择 外部连接。
配置 Ollama API,填写服务器地址,例如 http://10.0.10.33:14434,最后点击刷新按钮验证一下连接是否成功。
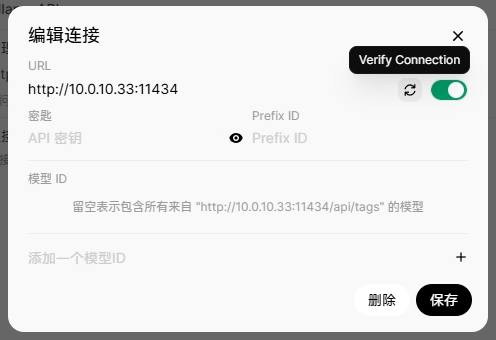
随后点击管理按钮,准备下载 deepseek-r1:7b 模型(访问 Ollama Library 在线查找模型库)。

耐心等待下载完毕。
聊天
等到模型下载完成后,返回首页,试着输入一段文字和它聊天吧。
